What is AnyToSpeech?
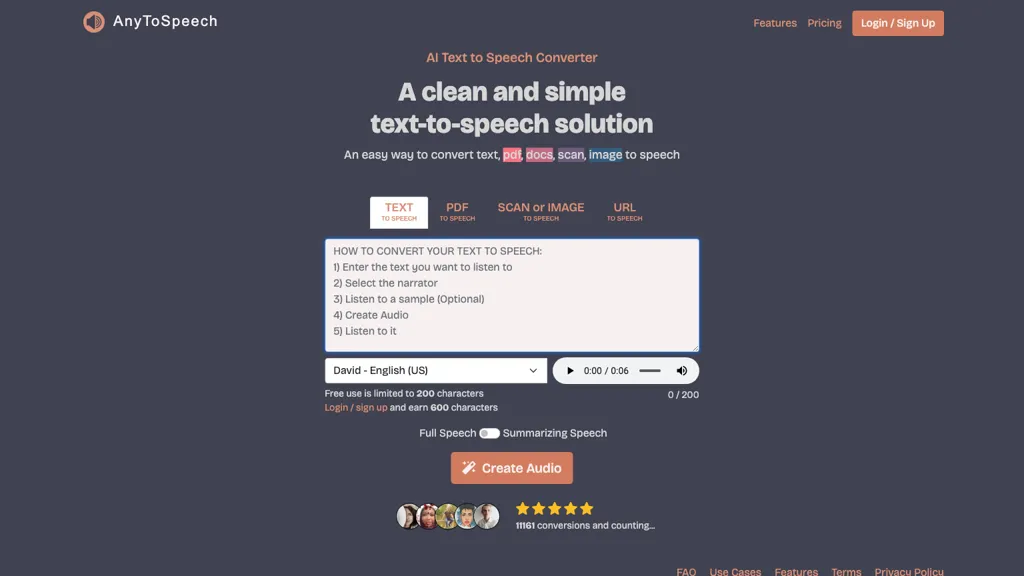
AnyToSpeech is an AI‑driven text‑to‑speech platform that converts written content—including plain text, PDFs, DOCX files, URLs, and images—into natural‑sounding audio files.
It provides over 100 voice options in 16 languages, allowing users to choose the style that best fits their project.
The voice‑cloning feature creates a custom voice from a 30‑second recording, which can then be applied to all conversion tools, including Speech‑to‑Speech that transcribes audio with OpenAI Whisper and regenerates the speech in the cloned voice while automatically removing filler words.
Image text can be extracted, translated into more than 30 languages, and spoken aloud, and transcriptions are downloadable in TXT or DOCX formats.
The service is available through a web interface and a free Android app, enabling on‑the‑go conversion of text, images, and audio.
AnyToSpeech pricing Subscription
Verify on the official pricing page.
View plansAnyToSpeech user reviews
Would you recommend AnyToSpeech?
AnyToSpeech's key features
-
Convert text to speech audio
-
PDF to MP3 conversion
-
Voice cloning in 30 seconds
-
Speech-to-text transcription
-
Image to speech extraction
-
URL to speech conversion
-
Mobile app for on‑the‑go
AnyToSpeech use cases
-
Convert long PDF reports into audio podcasts for remote teams to listen on the go, using AnyToSpeech's natural‑sounding voices across 16 languages and automatic filler‑word removal
-
Create a brand‑consistent, custom‑voice virtual assistant that reads out notifications, by cloning a short voice clip and deploying the 100+ voice options through the web and Android app
-
Transcribe and clean recorded lectures or webinars, then translate the transcriptions into multiple languages so the content can be shared with a global audience
Who is it for?
-
Content creators
-
Product designers
-
E-commerce sellers
-
Speech researchers
-
Language learners