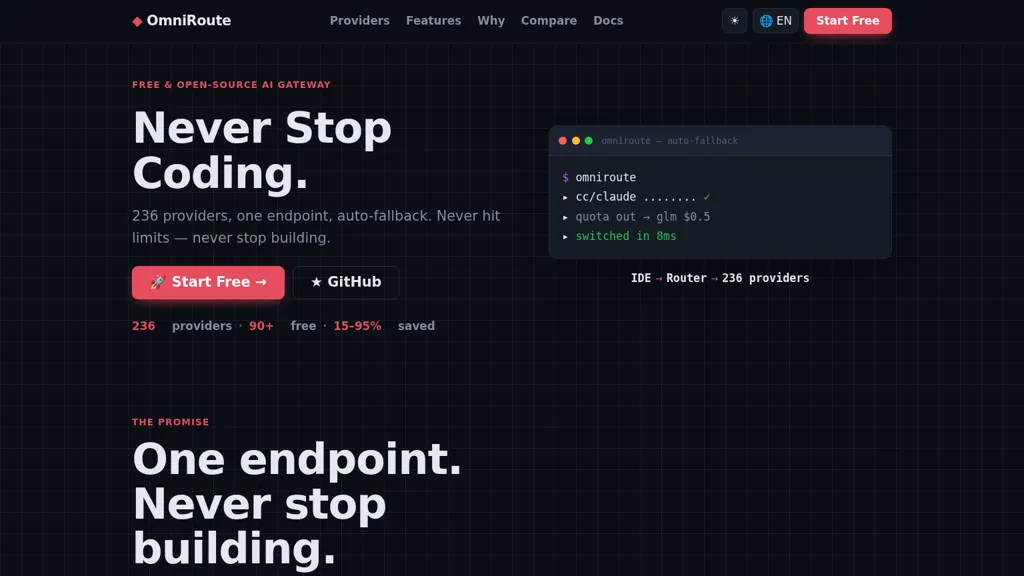
What is OmniRoute?
OmniRoute is an open-source AI gateway that routes requests to 236 LLM providers through a single /v1 endpoint, compatible with OpenAI, Claude, Gemini and local models.It implements auto-fallback and 17 routing strategies with tiered fallback and 9-factor scoring to maintain availability and reduce downtime.
Built-in RTK+Caveman stacked compression reduces tokens by 15–95% and includes persistent memory (FTS5 + Qdrant), circuit breakers, connection cooldowns and model lockouts for layered resilience.The gateway exposes MCP and A2A protocols, a 95-tool MCP server and cloud agent integrations for agent-native workflows and coding assistants.
Self-hostable with a local dashboard, per-provider proxying and TLS fingerprint stealth, OmniRoute stores encrypted local credentials and supports regional access.Provider catalog and free-tier tracking cover 90+ free providers with pool-deduped quota accounting to maximize available free tokens.
OmniRoute user reviews
Would you recommend OmniRoute?
OmniRoute's key features
-
Single-endpoint multi-provider AI gateway with auto-fallback across 236 providers (/v1 compatibility)
-
RTK + Caveman stacked token-compression pipeline (composable engines)
-
17 routing strategies with tiered fallback and 9-factor auto-scoring for cost/quota-aware routing
-
Three-layer resilience model: provider circuit breaker, connection cooldown, and model lockout
-
Built-in MCP server and A2A JSON-RPC agent protocol exposing the gateway as 95 tools across 30 scopes (cloud agents supported)
OmniRoute use cases
-
Create a resilient, cost-optimized AI inference layer by routing requests to 236 LLM providers through a single /v1 endpoint, using tiered fallback routing and provider quota tracking to ensure uptime and control spend while leveraging stacked token compression to reduce token costs
-
Build a privacy-first, self-hosted AI gateway for customer-facing chatbots and virtual assistants that uses persistent LLM memory for personalized conversations, agent-native integrations for complex workflows, and self-hosted analytics to keep data on-premises
-
Implement fault-tolerant multi-LLM automation pipelines for internal agents and RPA workflows, leveraging auto-fallback, resilience controls and MCP/A2A support for reliability, persistent memory for context continuity, and stacked token compression plus quota monitoring to optimize latency and API usage
Who is it for?
-
Developers
-
Devops engineers
-
System architects
-
Tech leads
-
Machine learning engineers