What is ImageBind by Meta?
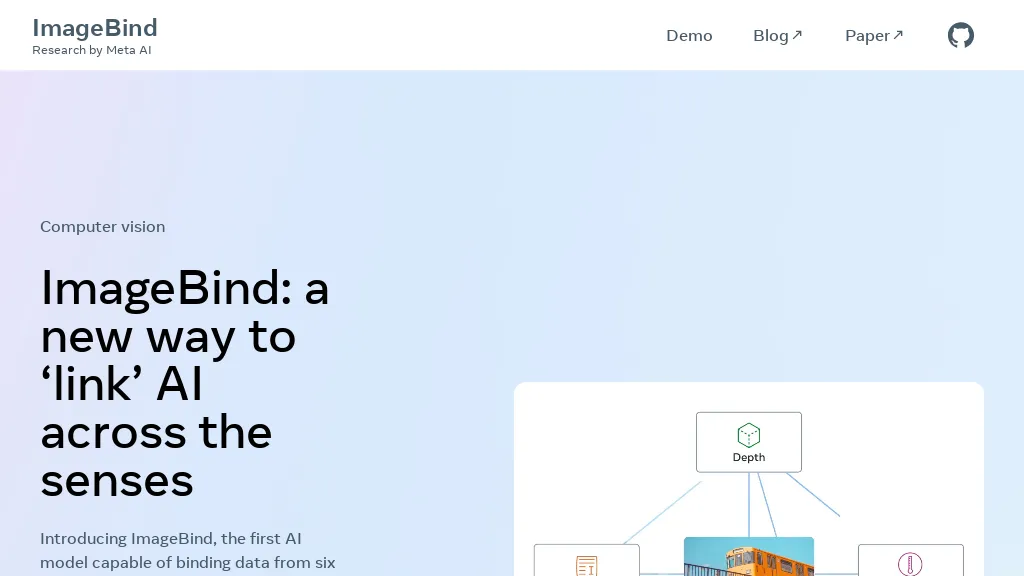
ImageBind by Meta AI is a multimodal AI model that simultaneously processes images, video, audio, text, depth, thermal, and inertial measurement unit (IMU) data. It learns a single embedding space that links these six modalities without explicit supervision, allowing seamless integration across sensory inputs.
The framework can enhance existing AI systems to accept any of the supported modalities, enabling cross‑modal search, multimodal arithmetic, and generation tasks. ImageBind demonstrates state‑of‑the‑art zero‑shot and few‑shot recognition performance, outperforming specialist models trained for individual modalities.
ImageBind by Meta user reviews
Based on 1 review, 0.0% of users recommend ImageBind by Meta.
0
recommend
1
don't
1 review
Disliked for
Inconsistent results
1 of 1
Missing features
1 of 1
Lacks integrations
1 of 1
Would you recommend ImageBind by Meta?
Recommend this tool?
ImageBind by Meta's key features
-
Image to audio retrieval
-
Video to audio suggestion
-
Multi-modal mapping support
-
Instant audio option generation
-
Multiple audio options per image
-
Audio to image generation
ImageBind by Meta use cases
-
Instantly correlate a security camera clip with corresponding audio and thermal footage to detect suspicious activity, leveraging ImageBind’s zero‑shot multimodal recognition without custom training.
-
Perform cross‑modal product search in an e‑commerce app: a user uploads a photo or voice description, and ImageBind retrieves matching listings using depth and IMU metadata for precise angle comparison.
-
Generate descriptive captions for museum exhibits by fusing high‑resolution images, ambient audio recordings, and depth maps, then feeding the multimodal embedding into a text generation pipeline.
Who is it for?
-
Machine learning engineers
-
Computer vision developers
-
Natural language engineers
-
Research scientists
-
Data analysts