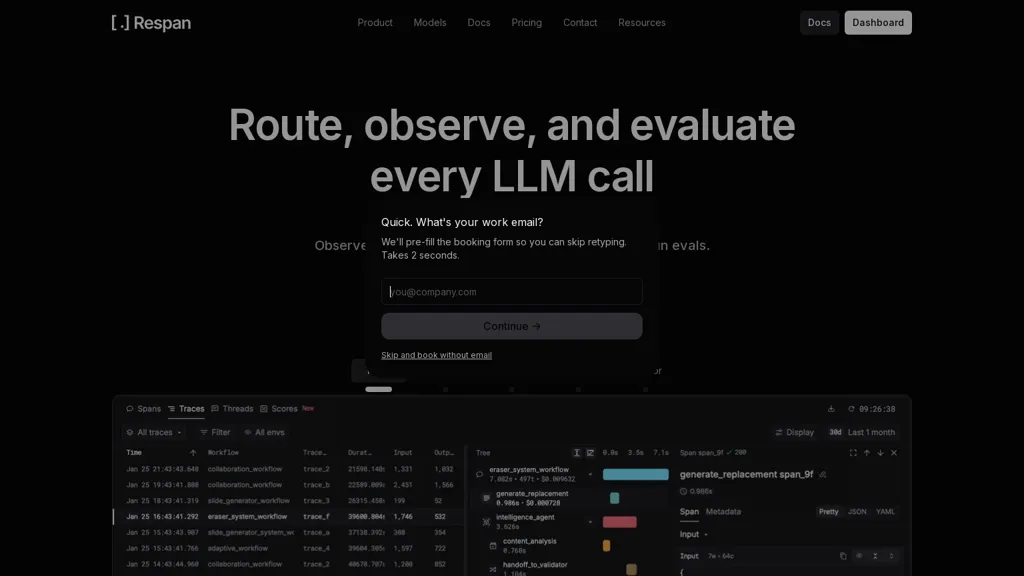
What is Respan AI?
Respan is an LLM engineering platform and API gateway for routing, observing, evaluating, and optimizing large language model calls.Route traffic to 500+ models with OpenAI-style API compatibility, provider passthrough, model fallbacks, load balancing, retries/backoff, and per-key spend controls.
Capture every request as a trace tree with latency spans, metadata, and session context to reproduce and inspect real production sessions.Monitor usage and performance with dashboards that slice metrics by model, user, key, or product and send alerts via Slack, email, or webhooks for cost, latency, and error thresholds.
Manage prompts, models, and workflows in the UI with version control, rollout logic, and integration hooks to promote changes to production.Run online evaluators on sampled production traffic combining automated checks, LLM judges, and human review to measure faithfulness, schema, relevance, and hallucination rates.
Export traces and datasets for experiments, compare prompt/model variants, cache repeat responses to reduce cost and latency, and enforce soft/hard API caps.Use a single gateway to deploy, monitor, and iterate on LLM-powered applications while preserving provider native SDK passthrough when needed.
Respan AI pricing Freemium
Verify on the official pricing page.
View plansRespan AI user reviews
Based on 1 review, 100.0% of users recommend Respan AI, rated highly for quality results.
Liked for
Would you recommend Respan AI?
Respan AI's key features
-
Route traffic to models with OpenAI-style API compatibility, provider passthrough, model fallbacks, load balancing, retries/backoff, and per-key spend controls
-
Capture every request as a trace tree with latency spans, metadata, and session context to reproduce and inspect production sessions
-
Monitor usage and performance with dashboards that slice metrics by model, user, key, or product and send alerts via Slack, email, or webhooks for cost, latency, and error thresholds
-
Manage prompts, models, and workflows in a UI with version control, rollout logic, and integration hooks to promote changes to production
-
Run online evaluators on sampled production traffic combining automated checks, LLM judges, and human review to measure faithfulness, schema compliance, relevance, and hallucination rates
Respan AI use cases
-
Route and scale production LLM traffic across 500+ providers using Respan’s OpenAI-compatible gateway, enforcing cost and latency limits, caching frequent responses, and automatically failing over to cheaper or lower-latency models to keep your application fast and affordable
-
Implement full trace-based observability and request tracing for all model calls with Respan’s dashboards and logs, making it easy to monitor latency, error rates, prompt-level usage, and generate SLA/compliance reports for debugging and audits
-
Manage prompts and model experiments using Respan’s prompt/version control and online evaluators to run A/B tests, safely roll out prompt updates, track performance across providers, and auto-select the best-performing model based on live evaluation metrics
Who is it for?
-
Ml engineers
-
Prompt engineers
-
Llm application engineers
-
Mlops engineers
-
Sre engineers