What is MagicAnimate Playground?
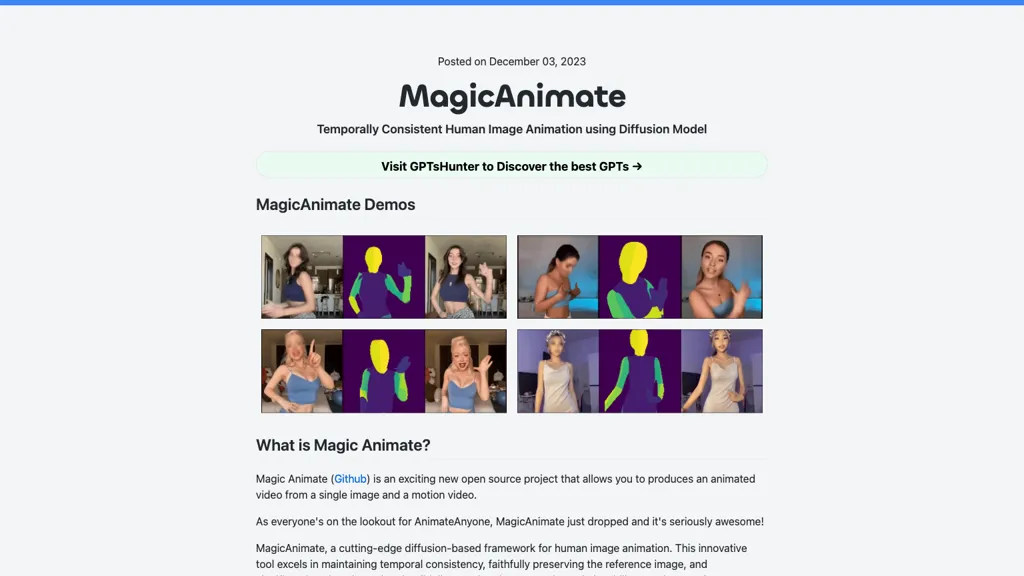
MagicAnimate delivers temporally consistent human image animation by combining a single reference image with a motion video. The system uses a diffusion model trained on Stable Diffusion V1.5 and a multi‑scale encoder‑decoder (MSE‑finetuned VAE) to preserve the visual identity while generating smooth motion.
It supports cross‑ID animation, allowing reference images from different domains such as anime, oil paintings, or movie characters to be animated with motion from any source, including unseen datasets. Integration with OpenPose enables the conversion of arbitrary videos into pose‑driven motion inputs, and the model can also animate text‑generated images from T2I diffusion models such as DALLE‑3.
The project is open‑source, hosted on GitHub, and can be run locally via a conda environment, or accessed through Hugging Face, Replicate, and Colab demos. A Replicate API endpoint is available for automated batch processing and integration into production pipelines.
MagicAnimate Playground user reviews
Based on 1 review, 100.0% of users recommend MagicAnimate Playground, rated highly for quality results.
Liked for
Would you recommend MagicAnimate Playground?
MagicAnimate Playground's key features
-
Animates image using motion video
-
Maintains temporal consistency
-
Cross-ID domain animation
-
Integrates DALLE3 text prompts
-
Uses OpenPose motion input
-
Replicate API video generation
-
StableDiffusion V1.5 base model
MagicAnimate Playground use cases
-
Generate dynamic product showcases for e-commerce sites by animating still product photos with pose‑driven motion, creating eye‑catching videos that boost click‑through rates without any video editing skills.
-
Build personalized virtual avatars for online meetings or gaming by uploading a portrait and letting MagicAnimate transfer your live pose onto a stylized character, enabling real‑time motion capture and expressive interactions.
-
Produce a cohesive animated comic strip from a series of static illustrations using batch image animation, preserving artistic style with the diffusion‑model VAE while automatically generating temporally consistent frames for smooth storytelling.
Who is it for?
-
Digital marketers
-
Animated animators
-
Product designers
-
Video editors
-
Content creators